Pandas dataframe:修订间差异
跳到导航
跳到搜索
无编辑摘要 |
(→list) |
||
| 第35行: | 第35行: | ||
l1[0] # get frist value | l1[0] # get frist value | ||
usys.utime(l1[0][7].value/10**9) * P.S. 日期型的字段转换后格式:Timestamp('2017-04-13 13:48:32'),pandas._libs.tslibs.timestamps.Timestamp. 可以使用 usys.utime(l1[0][7].value/10**9) 转换。 | usys.utime(l1[0][7].value/10**9) * P.S. 日期型的字段转换后格式:Timestamp('2017-04-13 13:48:32'),pandas._libs.tslibs.timestamps.Timestamp. 可以使用 usys.utime(l1[0][7].value/10**9) 转换。 | ||
=== CSV === | |||
==== read ==== | |||
# 默认: sep=',', quotechar='"' | |||
df1 = pandas.read_csv('test.csv', sep=',', quotechar='"', header=1) | |||
# names 列不足,以末尾对齐 | |||
df2 = pandas.read_csv('test.csv', sep=',', quotechar='"', header=None, names=['c1', 'c2']) | |||
[[分类:Develop]] | [[分类:Develop]] | ||
[[分类:Python]] | [[分类:Python]] | ||
[[分类:Pandas]] | [[分类:Pandas]] | ||
2024年7月19日 (五) 10:42的版本

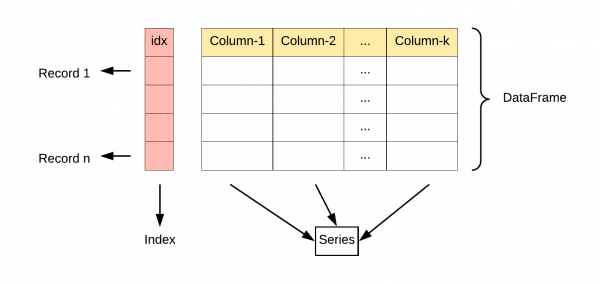
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
pandas dataframe conversion
dict
dict -> dataframe
d1 = {"columns":["Apple","Pear"],"data":[[12,0], [8,7], [1, 9]]}
df2 = pd.DataFrame(d1['data'])
Apple Pear
0 12 0
1 8 7
2 1 9
df2.columns=d1['columns']
Index(['Apple', 'Pear'], dtype='object')
dataframe -> dict
Syntax: DataFrame.to_dict(orient=’dict’, into=)
Parameters:
- orient: String value, (‘dict’, ‘list’, ‘series’, ‘split’, ‘records’, ‘index’) Defines which dtype to convert Columns(series into). For example, ‘list’ would return a dictionary of lists with Key=Column name and Value=List (Converted series).
- into: class, can pass an actual class or instance. For example in case of defaultdict instance of class can be passed. Default value of this parameter is dict.
Example
...
df2.to_dict('split')
{'index': [0, 1, 2], 'columns': ['Apple', 'Pear'], 'data': [[12, 0], [8, 7], [1, 9]]}
df2.to_dict('records')
[{'Apple': 12, 'Pear': 0}, {'Apple': 8, 'Pear': 7}, {'Apple': 1, 'Pear': 9}]
list
list -> dataframe
See also: dict -> dataframe
dataframe -> list
a1 = df1.values # values方法将dataframe转为numpy.ndarray
l1 = a1.tolist()
l1[0] # get frist value
usys.utime(l1[0][7].value/10**9) * P.S. 日期型的字段转换后格式:Timestamp('2017-04-13 13:48:32'),pandas._libs.tslibs.timestamps.Timestamp. 可以使用 usys.utime(l1[0][7].value/10**9) 转换。
CSV
read
# 默认: sep=',', quotechar='"'
df1 = pandas.read_csv('test.csv', sep=',', quotechar='"', header=1)
# names 列不足,以末尾对齐
df2 = pandas.read_csv('test.csv', sep=',', quotechar='"', header=None, names=['c1', 'c2'])